
AI red teamer (人工智能红队)系列07-人工智能基础-支持向量机 (SVM)
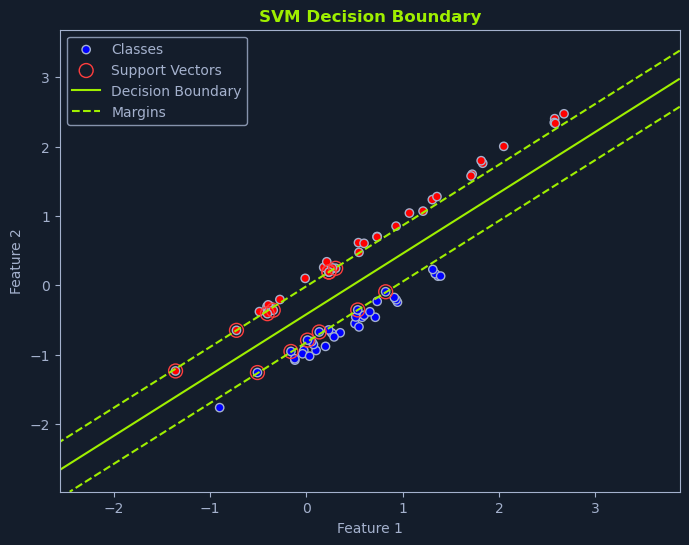
支持向量机(SVM)是一种强大的监督学习算法,适用于分类和回归任务。它们在处理高维数据以及特征与目标变量之间复杂的非线性关系时尤为有效。SVM 的目标是找到最优的 超平面,最大限度地分离不同类别或适合回归数据。
SVM 的目标是找到使 边距 最大化的超平面。边距是超平面与每个类的最近数据点之间的距离。这些最近的数据点称为 支持向量,对于定义超平面和边距至关重要。
线性 SVM
线性 SVM 用于数据可线性分离的情况,这意味着直线或超平面可以完美地分离类别。我们的目标是找到最优超平面,在正确分类所有训练数据点的同时,使边际最大化。
寻找最佳超平面
想象一下,你的任务是根据 "免费 "和 "金钱 "这两个词的频率,将电子邮件分为垃圾邮件和非垃圾邮件。如果我们将每封电子邮件绘制在一张图上,X 轴代表 "免费 "的频率,Y 轴代表 "金钱 "的频率,我们就可以直观地看到 SVM 的工作原理。
最佳超平面是使不同类别的最近数据点之间的边际最大化的超平面。这个边距称为 分离超平面。最接近超平面的数据点称为 支持向量,因为它们 "支持 "或定义了超平面和边际。
最大化边际值的目的是创建一个稳健的分类器。较大的边际允许 SVM 在不误判点的情况下容忍数据中的一些噪声或可变性。它还能提高模型的泛化能力,使其更有可能在未见过的数据上表现出色。
在图中描述的垃圾邮件分类场景中,线性 SVM 可识别出使最近的垃圾邮件与非垃圾邮件之间的距离最大化的线。这条线是对新邮件进行分类的决策边界。位于该线一侧的邮件被归类为垃圾邮件,而位于该线另一侧的邮件则被归类为非垃圾邮件。
超平面由一个等式定义:
w * x + b = 0w是权重向量,垂直于超平面。x是输入特征向量。b是偏置项,它使超平面相对于原点移动。
SVM 算法会在训练过程中学习 w 和 b 的最佳值。
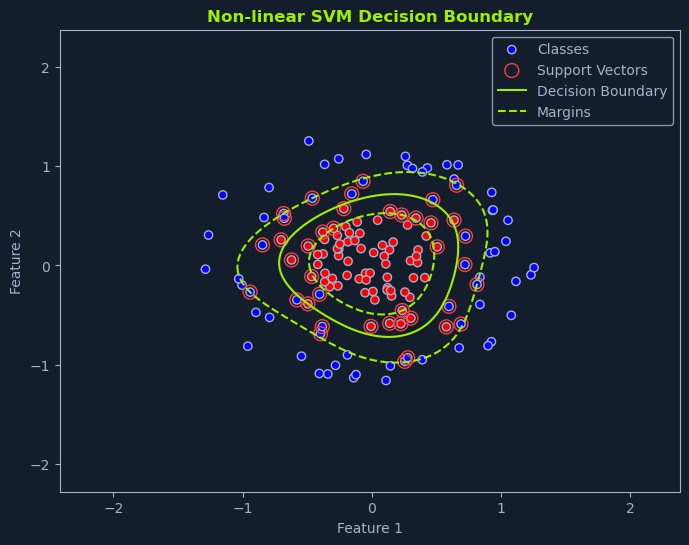
在现实世界的许多场景中,数据并不是线性可分的。这意味着我们无法绘制一条直线或超平面来完美地分离不同的类别。在这种情况下,非线性 SVM 就可以派上用场了。
核方法
非线性 SVM 使用一种称为核技巧的技术。这包括使用 核函数将原始数据点映射到一个更高维的空间,在这个空间中,原始数据点变得线性可分。
想象一下将桌子上的红色和蓝色混合弹珠分开的情景。如果这些弹珠混合成复杂的图案,你可能无法画出一条直线将它们分开。但是,如果你能把一些弹珠从桌子上拿起来(放到更高的维度),也许就能找到一个平面把它们分开。
这就是核函数的本质。它将数据转换到一个高维空间,在这个空间中可以找到一个线性超平面。当映射回原始空间时,该超平面对应于非线性决策边界。
核函数
非线性 SVM 中常用的核函数有几种:
多项式核:该核引入多项式项(如 x²、x³ 等)来捕捉特征之间的非线性关系。这就像是在决策边界上添加曲线。径向基函数(RBF)核:该内核使用高斯函数将数据点映射到高维空间。它是最流行、最通用的核函数之一,能够捕捉复杂的非线性模式。Sigmoid 核:该核类似于逻辑回归中使用的 sigmoid 函数。它通过将数据点映射到具有西格玛形决策边界的空间来引入非线性
核函数的选择取决于数据的性质和模型所需的复杂程度
图像分类
非线性 SVM 在图像分类等应用中特别有用。图像通常具有线性边界无法分离的复杂模式。
例如,想象一下对猫和狗的图像进行分类。这些特征可能是皮毛纹理、耳朵形状和面部特征。这些特征通常具有非线性关系。具有适当核函数的 非线性 SVM 可以捕捉这些关系,并有效地将猫图像和狗图像区分开来。
SVM 函数
要找到这个最佳超平面,需要解决一个优化问题。这个问题可以表述为
Minimize: 1/2 ||w||^2
Subject to: yi(w * xi + b) >= 1 for all iw是定义超平面的权重向量xi是数据点i的特征向量yi是数据点i的类别标签(-1 或 1)。b是偏置项
这种方法的目的是最小化权重向量的大小(使边际值最大化),同时确保所有数据点都能正确分类,边际值至少为 1。
数据假设
SVM 对数据的假设很少:
没有分布假设:SVM 对数据的基本分布不做强烈假设。处理高维度:它们在高维空间中非常有效,在这种空间中,特征的数量大于数据点的数量。对异常值的健壮性:SVM 对异常值的健壮性相对较好,它侧重于最大化边际,而不是完美拟合所有数据点。
SVM 是一种功能强大、用途广泛的算法,已在各种机器学习任务中证明行之有效。SVM 能够处理高维数据和复杂的非线性关系,是解决具有挑战性的分类和回归问题的重要工具。
Comments NOTHING