
AI red teamer (人工智能红队)系列19 - 人工智能基础 - 递归神经网络
递归神经网络 (RNNs)是一类人工神经网络,专门用于处理序列数据,其中数据点的顺序非常重要。传统的前馈神经网络只处理一次数据,与之不同的是,RNN 具有一种独特的结构,使其能够保持对过去输入的 "记忆"。这种记忆使它们能够捕捉序列中的时间依赖性和模式,因此非常适合自然语言处理、语音识别和时间序列分析等任务。
处理序列数据
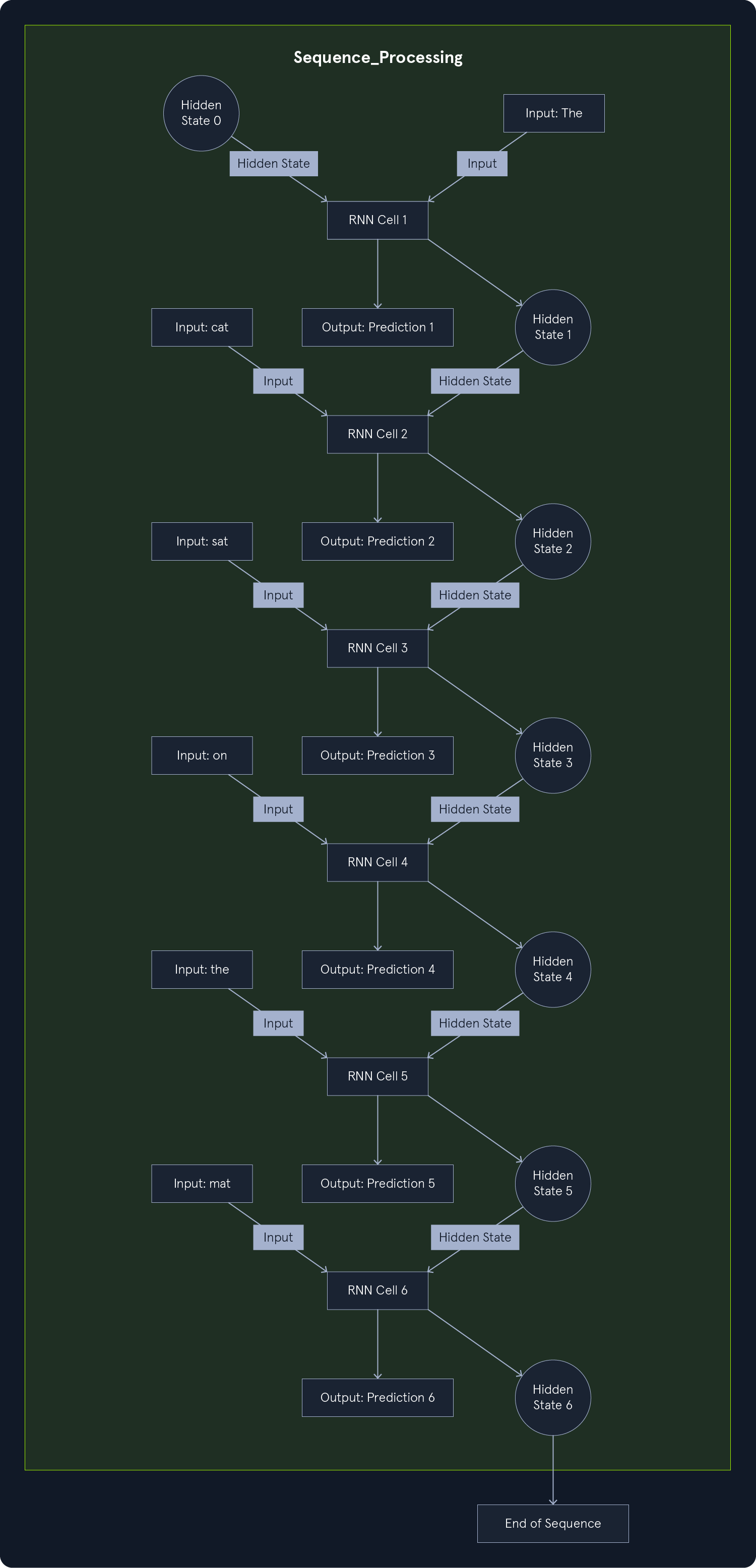
理解 RNNs 如何处理顺序数据的关键在于其递归连接。这些连接在网络中形成循环,使信息得以持续并从一个步骤传递到下一个步骤。想象一下 RNNs 逐字处理一个句子的情形。在遇到每个单词时,它都会考虑当前的输入,并结合之前单词的信息,从而有效地 "记住 "上下文。
这个过程可以形象地理解为一连串重复的模块,每个模块代表序列中的一个时间步骤。在每一步中,模块需要两个输入:
- 序列中的当前输入(如句子中的一个单词)
- 上一时间步的隐藏状态包含了从过去的输入中学到的信息。
然后,模块执行计算并产生两个输出结果:
- 当前时间步的输出(例如对下一个字的预测)
- 在序列的下一个时间步中传递一个更新的隐藏状态。
这种循环往复的信息流使 RNNs 能够学习整个序列中的模式和依赖关系,从而理解上下文并做出准确的预测。
举例, "The cat sat on the mat."。RNNs 处理这个句子的步骤如下:
- 从初始隐藏状态开始(通常设置为 0)。
- 处理单词 "The",并根据输入更新其隐藏状态。
- 处理单词 "cat",同时考虑单词本身和包含 "The "信息的隐藏状态。
- 继续以这种方式处理每个单词,每一步都在隐藏状态中积累上下文。
- 当 RNNs 读到 "mat "一词时,其隐藏状态将包含前面整个句子的信息,从而可以更准确地预测接下来可能出现的内容。
梯度消失问题
虽然 RNNs 在处理连续数据方面表现出色,但它们可能会面临梯度消失问题 。这个问题出现在训练过程中,特别是使用时间反向传播(BPTT)更新网络权重时。
在 BPTT 中,损失函数的梯度被计算出来,并通过网络传播回去,以调整权重,提高模型的性能。然而,当梯度在递归连接中回传时,它们会变得越来越小,最终消失到接近于零。这种消失的梯度阻碍了神经网络学习长期依赖关系的能力,因为与早期输入相关的权重得到的更新极少。
梯度消失问题在 RNNs中尤为明显,这是因为梯度会在不同时间步长间重复相乘。如果梯度很小(小于 1),它们的乘积就会随着在网络中的回传而呈指数递减。这意味着早期输入对最终输出的影响变得可以忽略不计,从而限制了 RNNs 捕捉长程依赖关系的能力。
LSTMs 和 GRU
为了解决梯度消失问题,研究人员开发了专门的 RNN 架构,即 长短期记忆(LSTM) 和 门控递归单元(GRU) 网络。这些架构引入了控制网络信息流的门控机制,使它们能够更好地捕捉长期依赖关系。
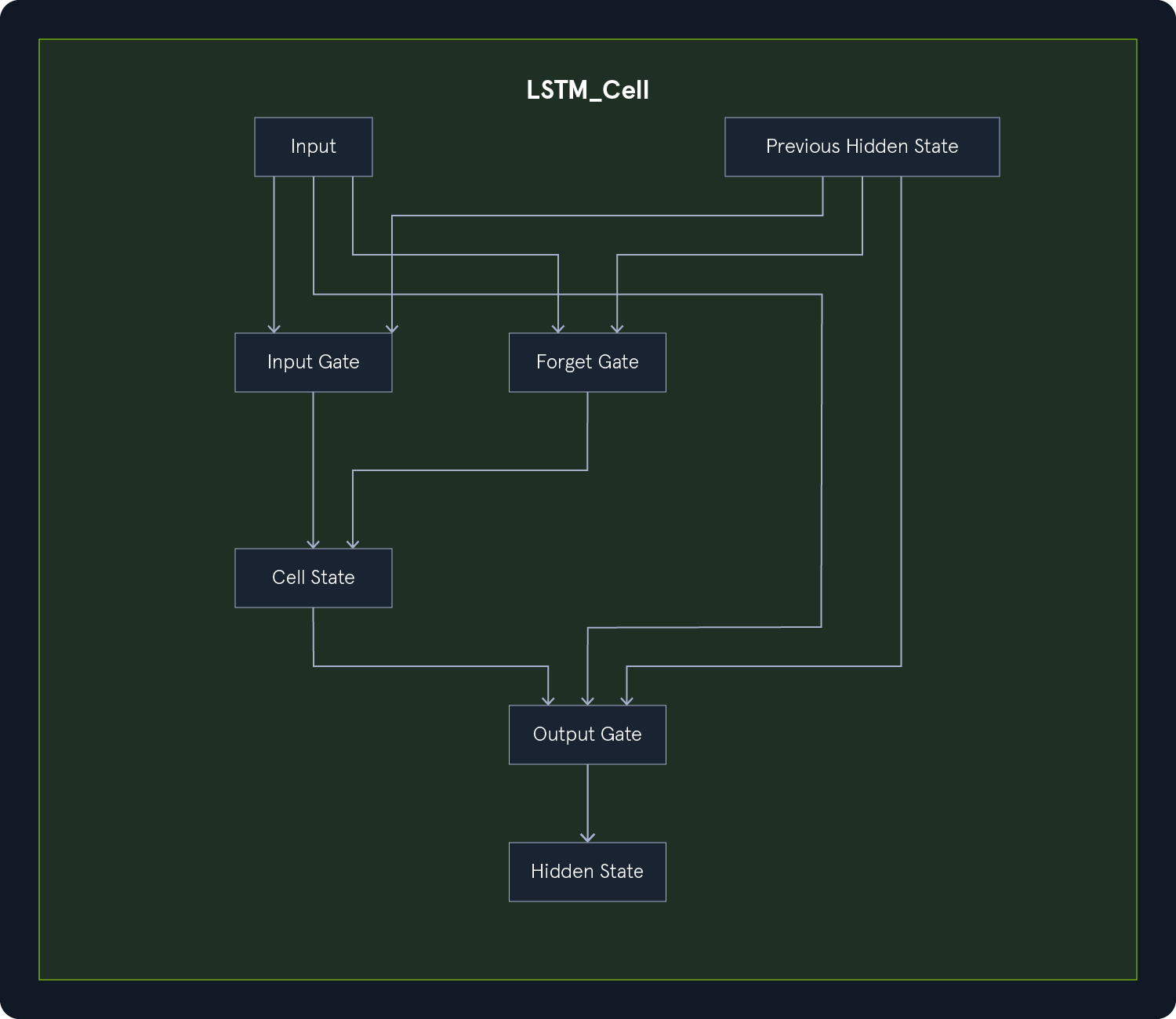
LSTM 包含可长期存储信息的存储单元。这些单元有三个门:
输入门:决定应向单元格状态添加哪些新信息。遗忘门:决定从单元格状态中删除哪些信息。输出门:决定单元状态中的哪些信息应用于输出。
补充:
单元状态: 贯穿图表顶部的一条水平线,允许信息不变地流动。
这些门使 LSTM 能够有选择地记忆或遗忘信息,从而缓解梯度消失问题,并使它们能够学习长期依赖关系。
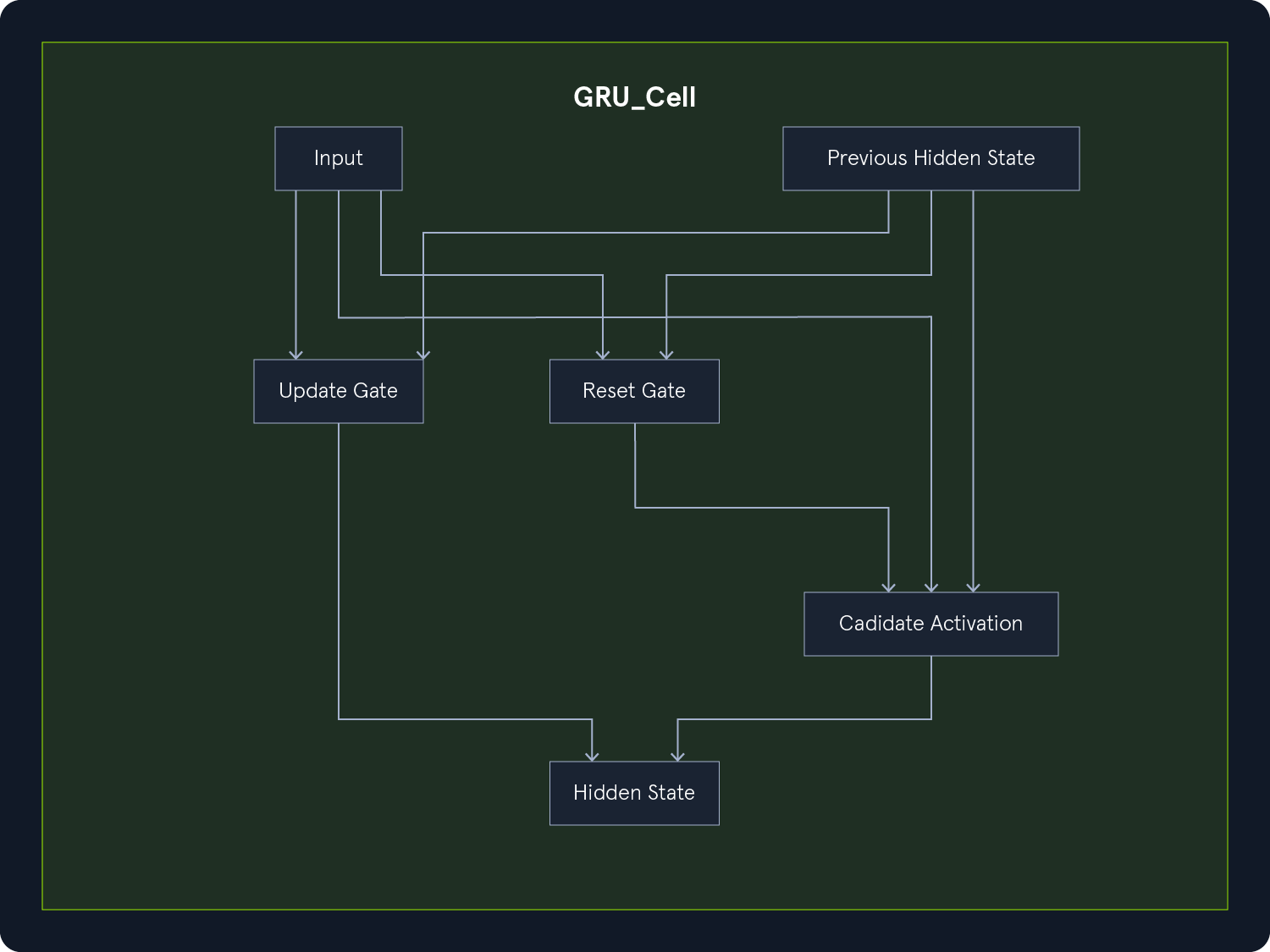
GRUs 提供了一种比 LSTM 更简单的替代方案,它只有两个门:
更新门:控制先前隐藏状态的保留程度。复位门:决定前一个隐藏状态与当前输入的结合程度。
在许多任务中,GRUs 的性能可与 LSTM 相媲美,同时由于其复杂性降低,计算效率更高。
事实证明,LSTM 和 GRUs 在解决梯度消失问题方面非常有效,在机器翻译、语音识别和情感分析等序列建模任务中表现优异。
双向 RNNs
除了向前处理序列的标准 RNNs 之外,还有 双向 RNNs。这些网络可同时向前和向后处理序列。这样,它们就能捕捉到过去和未来上下文的信息,这对于需要整个序列的任务(如自然语言处理)是非常有用的。
双向 RNNs 由两个 RNNs 组成,一个从左到右处理序列,另一个从右到左处理序列。两个 RNNs 的隐藏状态在每个时间步合并,产生最终输出。这种方法使神经网络能够考虑序列中每个元素的整个上下文,从而提高了许多任务的性能。
Comments NOTHING