
AI red teamer (人工智能红队)系列13 - 人工智能基础 - Q学习算法
Q-学习(英语:Q-learning)
Q-learning 是一种无模型的强化学习算法,它通过估计 Q 值来学习最优策略。Q 值代表一个智能体在给定状态下采取特定行动并在之后遵循最优策略所能获得的预期累积奖励。之所以称其为 "无模型",是因为智能体在学习时不需要先验的环境模型;它直接通过试错、与环境互动和观察结果来学习。
想象一下,一辆自动驾驶汽车正在学习如何在城市中导航。开始时,它对道路、交通信号灯或人行横道一无所知。通过 Q-learning,汽车在城市中探索,采取各种行动(加速、刹车、转弯),并获得奖励(快速安全到达目的地)或惩罚(碰撞或违反交通规则)。随着时间的推移,汽车会逐渐了解在不同情况下哪些操作会带来更高的奖励,最终掌握在该城市驾驶的技巧。
Q-Table
Q-learning 的核心是 Q-Table。该表是算法的核心组件,它存储了所有可能的状态-行动配对的 Q 值。可以把它想象成一个指导智能体决策过程的查找表。表格的行代表状态(例如,自动驾驶汽车在城市中的不同位置),列代表操作(例如,加速、刹车、左转、右转)。表格中的每个单元格都包含在特定状态下采取特定行动的 Q 值。
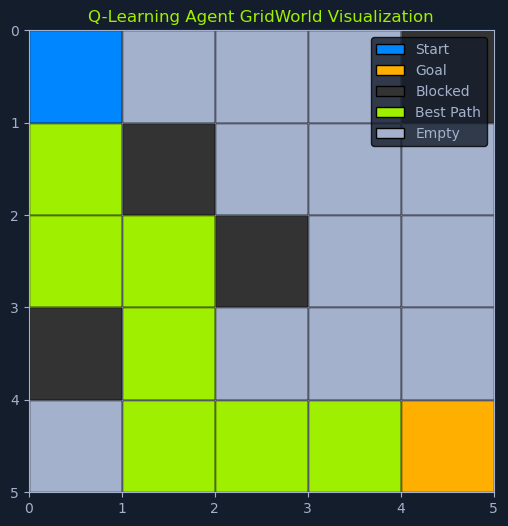
下面是一个网格世界环境的简单 Q-Table的示例,在这个环境中,机器人可以向上、向下、向左或向右移动。网格单元代表状态,动作代表可能的移动。
| State/Action | Up | Down | Left | Right |
|---|---|---|---|---|
| S1 | -1.0 | 0.0 | -0.5 | 0.2 |
| S2 | 0.0 | 1.0 | 0.0 | -0.3 |
| S3 | 0.5 | -0.5 | 1.0 | 0.0 |
| S4 | -0.2 | 0.0 | -0.3 | 1.0 |
在此表格中,S1、S2、S3 和 S4 是网格世界中的不同状态。单元格中的值代表了从每个状态采取每个行动的 Q 值。
特定状态-行动对的 Q 值使用 Q-learning 更新规则进行更新,该规则基于贝尔曼方程:
Q(s, a) = Q(s, a) + α * [r + γ * max(Q(s', a')) - Q(s, a)]Q(s, a)是在状态s中执行行动a的当前Q 值。α(α)是学习率,决定了新信息的权重。r是指从状态s开始执行行动a后得到的奖励。γ(gamma)是贴现因子,决定了未来回报的重要性。max(Q(s',a'))是下一个状态s'和任何动作a'的最大Q 值。
以更新网格世界环境中机器人的 Q 值为例。
- 机器人当前处于
S1状态。 - 它采取
Right行动,移动到状态S2。 - 达到状态
r = 0.5后,它将获得奖励S2。 - 学习率
α = 0.1。 - 折扣系数
γ = 0.9。 - 下一个状态
S2的最大Q 值是max(Q(S2, Up), Q(S2, Down), Q(S2, Left), Q(S2, Right)) = max(0.0, 1.0, 0.0, -0.3) = 1.0。
使用 Q-learning 更新规则:
Q(S1, Right) = Q(S1, Right) + α * [r + γ * max(Q(S2, a')) - Q(S1, Right)]
Q(S1, Right) = 0.2 + 0.1 * [0.5 + 0.9 * 1.0 - 0.2]
Q(S1, Right) = 0.2 + 0.1 * [0.5 + 0.9 - 0.2]
Q(S1, Right) = 0.2 + 0.1 * 1.2
Q(S1, Right) = 0.2 + 0.12
Q(S1, Right) = 0.32更新后,从状态 S1 开始采取动作 Right 的新 Q 值为 0.32 。这个更新值反映了机器人从进入状态 S2 并获得奖励的经验中学习到的知识。
Q-Learning 算法
Q-learning 算法是一个行动选择、观察和 Q 值更新的迭代过程。智能体不断与环境互动,从经验中学习并改进其策略,以实现累积奖励的最大化。
以下是相关步骤的详细介绍:
初始化:Q-table将被初始化,通常使用任意值(例如,全部为零),或者使用一些已有的知识。该表将随着智能体的学习而更新。选择行动:在当前状态下,智能体选择要执行的行动。这种选择涉及探索(尝试新行动以发现潜在的更好策略)和利用(使用当前最熟悉的行动以获得最大回报)之间的平衡。这种平衡既能确保智能体充分探索环境,又能充分利用现有知识。采取行动并观察:智能体在环境中执行选定的行动,并观察后果。这包括它在采取行动后过渡到的新状态以及从环境中获得的直接奖励。这些观察结果将为智能体提供有关其行动效果的宝贵反馈。更新 Q 值:使用Q-learning更新规则更新状态-行动对的Q 值,该规则包含从新状态接收到的和估计的未来奖励。更新状态:智能体将其当前状态更新为采取该行动后过渡到的新状态。这为算法的下一次迭代奠定了基础。迭代:重复步骤 2-5,直到Q 值收敛到最佳值,表明智能体已学习到有效策略,或满足预定的停止条件(如最大迭代次数或时间限制)。
这种迭代过程允许智能体不断学习和完善其策略,提高其决策能力,并随着时间的推移最大化其累积奖励。
最终,智能体会沿着累积奖励最大化的路径,从起点导航到目标。
Exploration-Exploitation Strategy (探索-利用策略)
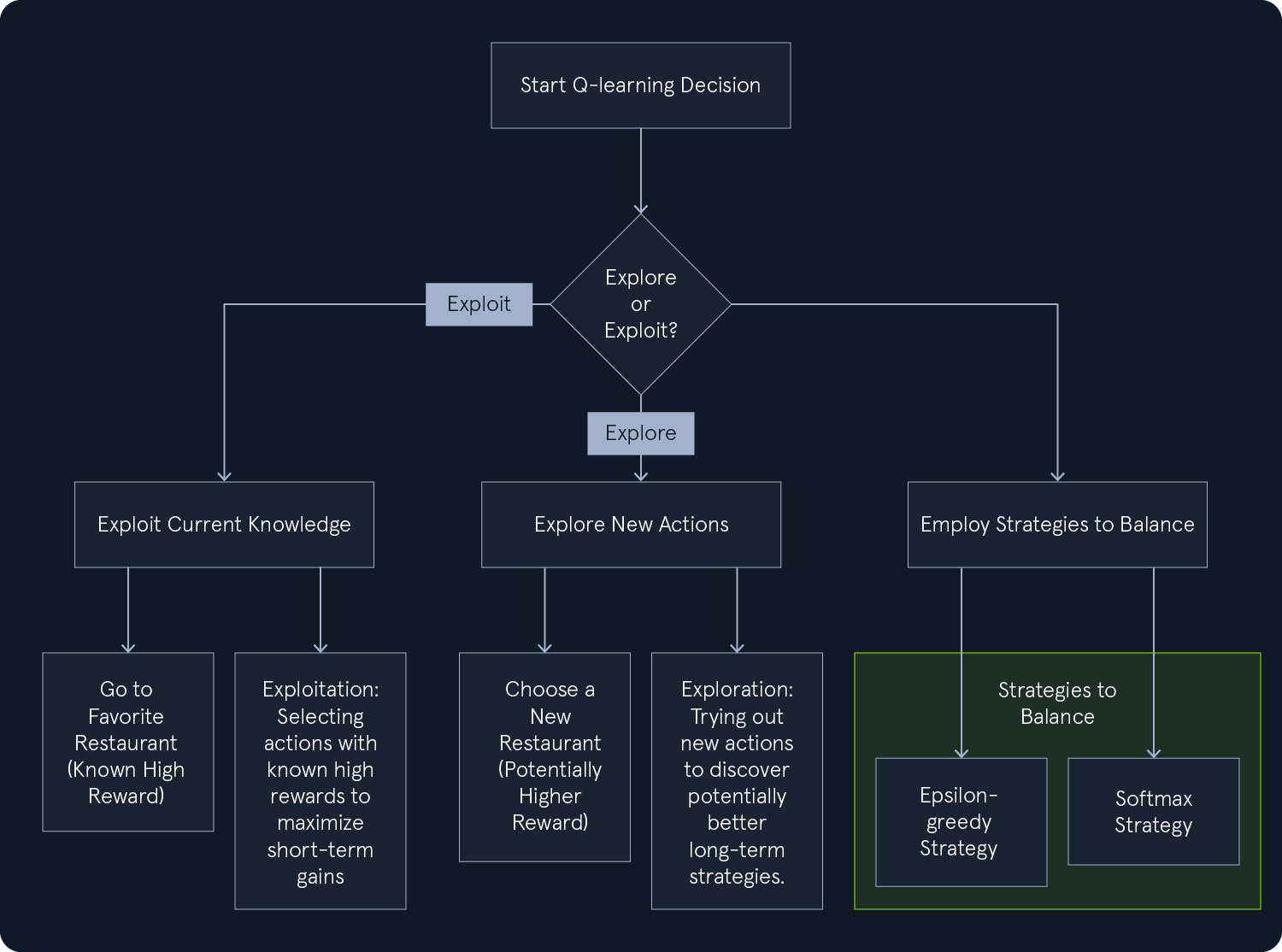
在 Q-learning 中,智能体面临着一个基本的两难选择:它是应该探索新的行动以发现潜在的更好策略,还是应该利用现有的知识并选择过去曾产生过高回报的行动?这就是探索与利用之间的权衡,也是强化学习的一个重要方面。
想想看,这就像选择一家餐馆共进晚餐一样。你可以利用已有的知识,去你最喜欢的餐厅,因为你知道那里的食物一定会让你大快朵颐。或者,你也可以去探索一家新的餐厅,碰碰运气,发现一家你可能会更喜欢的隐藏的宝藏。
Q-learning 采用各种策略来平衡探索和利用。我们的目标是找到一种平衡,让智能体既能有效学习,又能获得最大回报。
探索:鼓励智能体尝试不同的行动,即使这些行动之前没有带来高回报。这有助于智能体发现新的和潜在的更好策略。利用:该策略侧重于选择之前已获得高回报的行动。它允许智能体利用现有知识,最大化短期收益。
Epsilon-Greedy Strategy ε-贪婪策略
epsilon-greedy 策略 为平衡 Q-learning 中的探索和利用提供了一种简单而有效的方法。它在智能体的行动选择中引入了随机性,防止智能体总是默认相同的行动,从而可能错过更多有价值的选择。
epsilon-greedy策略 鼓励您探索新的选择,同时还允许您享受已知的最爱。在概率 epsilon(ε)的情况下,您可以大胆尝试随意选择一家咖啡店,从而有可能发现隐藏的瑰宝。如果概率为 1-epsilon,您就会坚持去老地方,确保获得满意的咖啡体验。
epsilon 的值是一个关键参数,可以随着时间的推移进行调整,以微调探索和利用之间的平衡。
高 Epsilon(例如 0.9):高 Epsilon 值最初会促进更多的探索。这就好比初来乍到,急于尝试不同的咖啡店,以找到最好的一家。低 Epsilon(例如 0.1):随着经验的积累和偏好的发展,您可能会降低 Epsilon。这就好比您成为最喜欢的咖啡店的常客,同时偶尔也会尝试新的咖啡店。
数据假设
Q-learning 对数据的假设极少:
马尔科夫特性:它假定环境满足马尔科夫特性,即下一个状态只取决于当前状态和操作,而不取决于之前的状态和操作历史。静态环境:它假定环境动态(过渡概率和奖励函数)不随时间变化。
小结
Q-learning 是一种功能强大、用途广泛的算法,用于学习强化学习问题中的最优策略。它能够在没有环境模型的情况下进行学习,因此适用于环境动态未知或复杂的各种应用。
Comments NOTHING