
AI red teamer (人工智能红队)系列14- 人工智能基础 - SARSA算法
SARSA算法是机器学习领域的一种强化学习算法,得名于“状态-动作-奖励-状态-动作”(State–Action–Reward–State–Action)的英文首字母缩写。
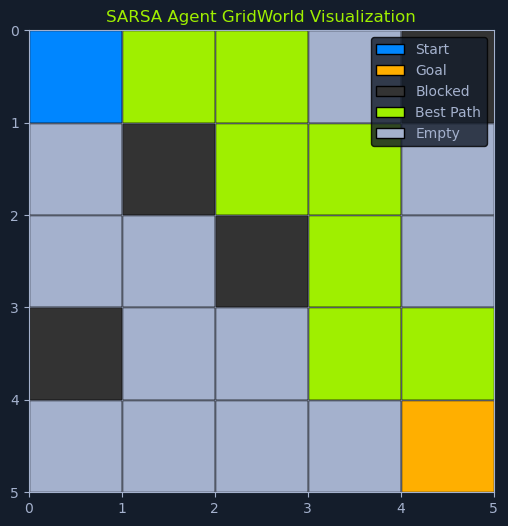
SARSA 是一种无模型强化学习算法,它通过直接的环境交互来学习最优策略。Q-learning 根据下一状态的最大 Q 值更新其 Q 值,而 SARSA 则根据下一状态的 Q 值和在该状态下采取的实际行动更新其 Q 值。这一关键区别使 SARSA 成为一种 基于策略的算法,这意味着它可以学习当前遵循的策略值。Q-learning 是非策略,它学习的是与当前策略无关的最优策略值。
SARSA 的更新规则是
Q(s, a) <- Q(s, a) + α * (r + γ * Q(s', a') - Q(s, a))这里,s 是当前状态,a 是当前行动,r 是得到的奖励,s' 是下一个状态,a' 是下一个行动,α 是学习率,γ 是折扣因子。Q(s',a') 项反映了当前策略决定的下一个状态-行动对的预期未来回报。
这种保守的方法使 SARSA 适合于需要严格遵循策略的环境。同时,Q-Learning 的探索性更强,在某些情况下能更有效地找到最优策略。
想象一下,一个机器人正在学习如何在一个有障碍物的房间中导航。SARSA 通过考虑一个动作的直接回报以及在新状态下采取的下一个动作的后果,引导机器人学习一条安全的路径。这种谨慎的方法可以帮助机器人避免可能导致碰撞的危险行动,即使这些行动最初看起来很有希望。
SARSA 算法的步骤如下:
初始化:为每个状态-动作对用任意值(通常为 0)初始化Q 表。此表将存储不同状态下动作的估计Q 值。选择行动:在当前状态s中,选择一个要执行的行动a。这种选择通常基于探索-利用策略,如epsilon-greedy,在探索新行动和利用已知能产生高回报的行动之间取得平衡。采取行动并观察:在环境中执行选定的行动a,并观察下一个状态s'和获得的奖励r。这一步涉及与环境互动,并收集有关行动后果的反馈。选择下一步行动:在下一个状态s'中,根据当前策略(例如,epsilon-greedy)选择下一步行动a'。这一步对于SARSA的随策略性质至关重要,它考虑的是下一个状态下的实际行动,而不仅仅是理论上的最优行动。更新 Q 值:更新状态-动作对 (s,a) 的Q 值。更新状态和操作:将当前状态和操作更新为下一个状态和操作:s = s',a = a'。这将为算法的下一次迭代做好准备。迭代:重复步骤 2-6,直到Q 值收敛或达到最大迭代次数。这种迭代过程允许智能体不断学习和完善其策略。
On-Policy Learning 策略学习
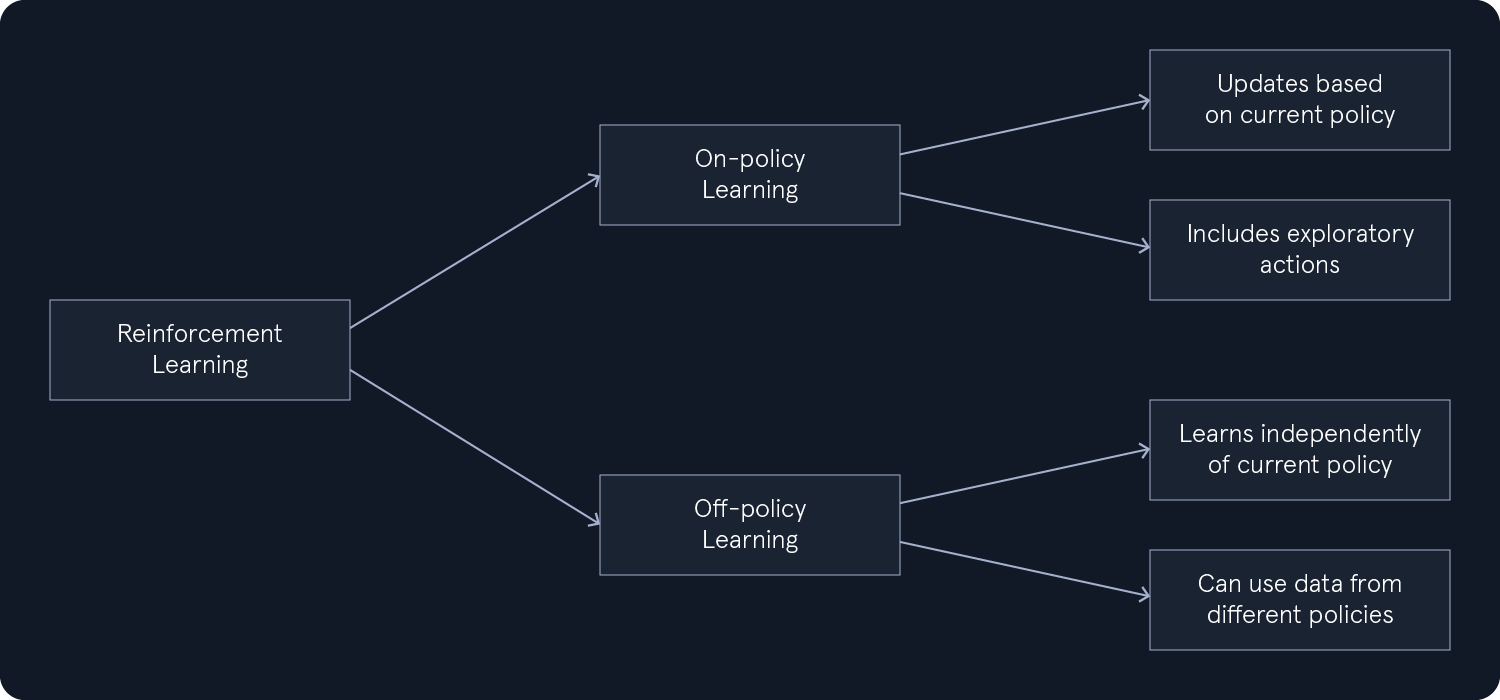
在强化学习中,学习过程可分为两种主要方法:on-policy 学习和 off-policy 学习。这种区分源于算法如何更新它们对行动值的估计,而行动值对确定最优策略至关重要。
策略学习:在策略学习中,算法会学习当前策略的值。这意味着,估计行动值的更新是基于执行当前策略时采取的行动和获得的奖励,包括任何探索性行动。非策略学习:相比之下,非策略学习允许算法学习最优策略,而不依赖于行动选择所遵循的策略。这意味着算法可以从不同策略生成的数据中学习,从而有利于探索和学习历史数据。
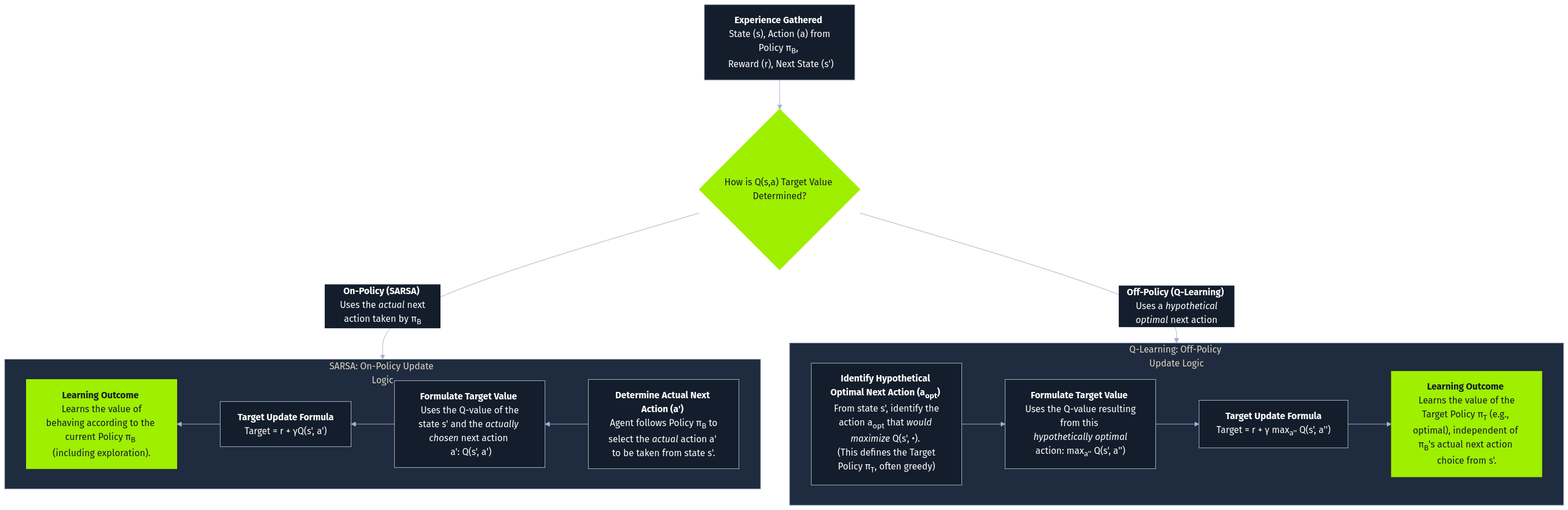
SARSA 的策略性源于其独特的更新规则。它使用下一个状态的 Q 值,并根据当前策略在下一个状态中采取的实际行动,来更新当前状态-行动对的 Q 值。这与 Q-learning 不同,后者使用下一状态中所有可能行动的最大 Q 值,与当前策略无关。
这种区别具有重要意义:
学习当前策略的价值:SARSA会学习当前策略的价值,包括探索步骤。这意味着它能估算出根据当前策略采取行动的预期回报,其中可能涉及一些探索性的步骤。安全性和稳定性:在安全性和稳定性至关重要的情况下,按策略学习是非常有利的。由于SARSA通过遵循当前政策进行学习,因此它不太可能探索可能导致负面后果的潜在危险或不稳定行动。探索影响:探索策略(例如,epsilon-greedy)会影响学习。SARSA学习策略的价值,包括探索,因此学习到的Q 值反映了探索和利用之间的平衡。
从本质上讲,SARSA 是 "在工作中 "学习的,它会根据在遵循当前策略时采取的行动和获得的奖励不断更新其估计值。这使它适用于优先学习安全稳定的策略的场景,即使这意味着可能会牺牲一些优化性。
SARSA 中的探索-利用策略抉择 (Exploration-Exploitation Strategies)
与 Q-learning 一样,SARSA 也面临着探索-利用的两难选择。智能体必须在探索新行动以发现潜在的更好策略和利用现有知识以获得最大回报之间取得平衡。探索-开发策略的选择会影响学习过程和由此产生的策略。
ε贪心策略
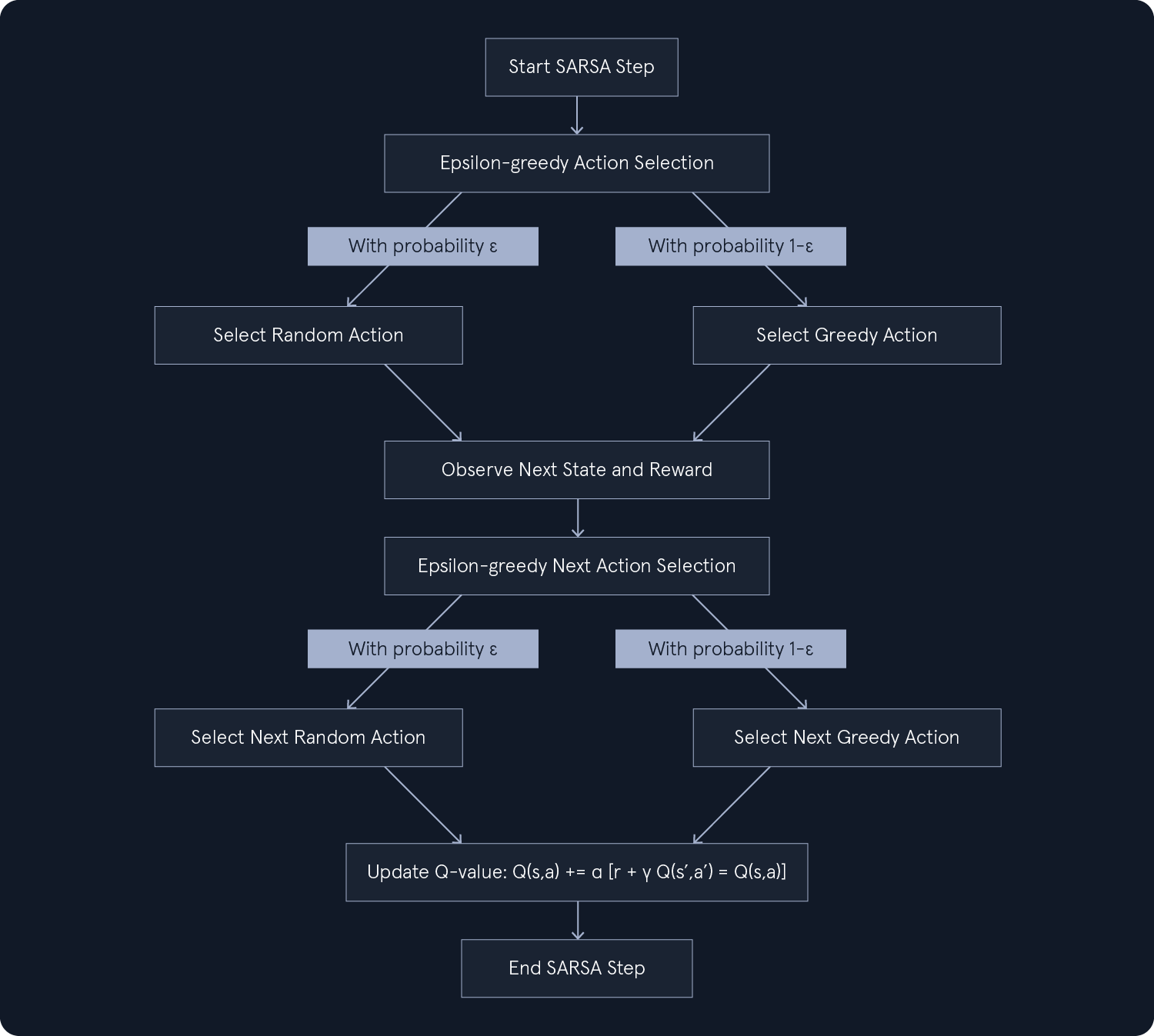
正如 Q-learning 所讨论的那样,epsilon-greedy 策略包括选择概率为 epsilon 的随机行动(ε)和概率为 1-ε 的贪婪行动(最高 Q 值)。这种方法通过偶尔选择随机行动来发现潜在的更好选择,从而在探索和利用之间取得平衡。
在 SARSA 中,epsilon-greedy 策略会导致更谨慎的探索。智能体会考虑下一个状态中探索行动的潜在后果,确保它们不会偏离已知的良好策略太远。
Softmax策略

softmax 策略根据行动的 Q 值分配概率,Q 值越高,概率越大。这使得探索过程更加平滑,中等偏上 Q 值的行动仍可被选中,从而促进探索和开发的平衡。
在 SARSA 中,softmax 策略可以带来更细致入微的适应性行为。它鼓励代理探索不一定是最好但仍有希望的行动,从而可能带来更好的长期结果。
在 SARSA 中,探索-开发策略的选择取决于具体问题以及安全与优化之间的理想平衡。探索性更强的策略可能会导致更长的学习过程,但有可能获得更优化的策略。更保守的策略可能会导致更快的学习过程,但也有可能导致避免风险行动的次优策略。
收敛和参数调整
与其他迭代算法一样,SARSA 需要仔细调整参数,以确保收敛到最优策略。强化学习中的收敛是指算法达到一个稳定的解决方案,在这个解决方案中,Q 值不再随着进一步的训练而发生显著变化。这表明代理已经学会了一种能有效实现奖励最大化的策略。
影响学习过程的两个关键参数是 学习率 (α) 和 折扣系数 (γ) :
学习率 (α):控制每次迭代中Q 值更新的程度。α越高,更新越快,但会导致不稳定;α越低,收敛越稳定,但会减慢学习速度。折扣系数 (γ):决定未来奖励相对于眼前奖励的重要性。γ越高(接近 1),越强调长期回报;γ越低,越优先考虑即时回报。
调整这些参数通常需要通过实验来找到一个平衡点,以确保稳定高效的学习。网格搜索或交叉验证等技术可以系统地探索不同的参数组合,以确定特定问题的最佳设置。
SARSA 的收敛也取决于探索-利用策略和环境的特点。在特定条件下,例如当学习率足够小,并且探索策略确保所有状态-动作对被无限次访问时,SARSA保证收敛到最优策略。
数据假设
SARSA 与 Q-learning 的假设类似:
马尔科夫特性:它假定环境满足马尔科夫特性,即下一个状态只取决于当前状态和操作,而不取决于之前的状态和操作历史。静态环境:它假定环境动态(过渡概率和奖励函数)不随时间变化。
小结
SARSA 是一种有价值的强化学习算法,它提供了一种按策略学习的方法,使其适用于对安全性和稳定性有严格要求的场景。它通过遵循特定策略进行学习的能力使其能够找到有效的解决方案,同时避免潜在的有害操作。
Comments NOTHING