
AI red teamer (人工智能红队)系列30 – 人工智能信息安全应用 – 从零构建异常流量检测模型
概述
异常检测可识别严重偏离常规的数据点。在网络安全中,此类异常可能预示着恶意活动、网络入侵或其他安全漏洞。本文将介绍如何使用随机森林算法构建一个有效的网络流量异常检测模型。
异常流量检测原理
网络异常检测是网络安全的重要组成部分,通过分析网络流量模式来识别潜在的安全威胁。当网络流量表现出与正常基线显著不同的特征时,可能表明存在以下情况:
- 恶意软件感染
- 数据泄露
- 拒绝服务攻击
- 内部威胁
- 系统配置错误
随机森林算法详解
随机森林是一种集成机器学习算法,通过构建多个决策树并汇总它们的预测结果来提高模型性能。
核心原理
在分类任务中,每棵决策树都会为一个类别投票,最终选择获得多数票的类别作为预测结果。在回归任务中,最终预测是各决策树输出的平均值。
关键优势
减少过拟合:通过组合多棵决策树的输出,随机森林的泛化能力通常优于单棵决策树
处理高维数据:能够有效处理复杂的高维特征空间
鲁棒性强:对噪声和异常值具有较强的抗干扰能力
构建过程
随机森林的构建涉及三个关键步骤:
- Bootstrap抽样:通过有放回抽样创建多个训练数据子集,每个子集用于训练一棵独立的决策树
- 特征随机选择:在构建每棵树的过程中,每次分割时随机选择特征子集,确保树之间的多样性并减少相关性
- 集成预测:所有树训练完成后,分类任务采用多数投票,回归任务计算预测值的平均值
异常检测应用
在异常检测场景中,随机森林模型仅使用代表正常情况的数据进行训练。对于新的、未见过的数据点,模型会根据学习到的正常行为模式进行评估。不符合正常模式或产生低置信度预测的数据点将被标记为潜在异常。
NSL-KDD 数据集介绍
NSL-KDD数据集是网络入侵检测研究领域的标准基准数据集,它在原始KDD Cup 1999数据集的基础上进行了重要改进:
- 消除冗余记录:移除了重复的数据条目,提高数据质量
- 平衡类别分布:纠正了原始数据集中的类别不平衡问题
- 标准化评估:为各种入侵检测模型提供统一的性能评估标准
该数据集包含正常和恶意网络活动的标注实例,支持二元分类(正常vs异常)和多类分类(针对特定攻击类型)任务,使其成为开发和测试入侵检测技术的宝贵资源。
环境准备与数据获取
下载数据集
在加载 NSL-KDD 数据集之前,我们必须从提供的 URL 中获取该数据集。我们可以使用 Python 的标准库下载 .zip 文件,然后将其解压到本地进行进一步处理。
import requests
import zipfile
import io
# NSL-KDD数据集下载URL
url = "https://academy.hackthebox.com/storage/modules/292/KDD_dataset.zip"
# 下载并解压zip文件
response = requests.get(url)
z = zipfile.ZipFile(io.BytesIO(response.content))
z.extractall('.') # 解压到当前目录导入必要的python模块
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import (accuracy_score, precision_score, recall_score,
f1_score, confusion_matrix, classification_report)
import seaborn as sns
import matplotlib.pyplot as plt
import joblib这些模块的功能分工:
numpy和pandas:数据加载和处理RandomForestClassifier:随机森林算法实现train_test_split:数据集分割sklearn.metrics:模型评估指标seaborn和matplotlib:数据可视化joblib:模型序列化和保存
数据加载与初步探索
定义列名和文件路径
NSL-KDD数据集包含41个特征和1个标签列。我们需要为这些列定义有意义的名称:
# 设置数据集文件路径
file_path = r'KDD+.txt'
# 定义NSL-KDD数据集的列名
columns = [
'duration', 'protocol_type', 'service', 'flag', 'src_bytes', 'dst_bytes',
'land', 'wrong_fragment', 'urgent', 'hot', 'num_failed_logins', 'logged_in',
'num_compromised', 'root_shell', 'su_attempted', 'num_root', 'num_file_creations',
'num_shells', 'num_access_files', 'num_outbound_cmds', 'is_host_login', 'is_guest_login',
'count', 'srv_count', 'serror_rate', 'srv_serror_rate', 'rerror_rate', 'srv_rerror_rate',
'same_srv_rate', 'diff_srv_rate', 'srv_diff_host_rate', 'dst_host_count', 'dst_host_srv_count',
'dst_host_same_srv_rate', 'dst_host_diff_srv_rate', 'dst_host_same_src_port_rate',
'dst_host_srv_diff_host_rate', 'dst_host_serror_rate', 'dst_host_srv_serror_rate',
'dst_host_rerror_rate', 'dst_host_srv_rerror_rate', 'attack', 'level'
]这些列包含以下类型的信息:
- 基本连接特征:
duration、src_bytes、dst_bytes等 - 分类特征:
protocol_type、service、flag等 - 统计特征:各种错误率和连接计数
- 标签:
attack(攻击类型)和level(严重程度)
加载数据集
定义好文件路径和列名后,我们将数据加载到 pandas DataFrame 中。这将为数据集提供结构化的表格表示,使其更易于检查、预处理和可视化。
执行此代码后,我们就得到了一个 DataFrame df,其中包含 NSL-KDD 数据集中的所有数据和适当的列标题。数据帧已准备就绪,可进行进一步检查、清理和预处理步骤。在继续之前,我们可以简要检查数据集的结构,检查是否有缺失值,并确认所有特征都符合其预期的数据类型。
# 将NSL-KDD数据集读入DataFrame
df = pd.read_csv(file_path, names=columns)
# 查看数据集基本信息
print("数据集形状:", df.shape)
print("\n前5行数据:")
print(df.head())
# 检查缺失值
print("\n缺失值统计:")
print(df.isnull().sum().sum())数据预处理
数据预处理是机器学习工作流程中的关键步骤,将原始网络流量数据转换为适合模型训练的格式。
创建分类目标变量
本节准备 NSL-KDD 数据集,以训练随机森林异常检测模型。主要目标是通过创建分类目标、编码分类变量和选择重要数字特征,将原始网络流量数据转换为可用格式。我们将生成二元和多类目标,确保分类数据可由机器读取,并保留对检测异常流量模式至关重要的数字指标。
二元分类目标
二进制分类目标可识别网络流量是正常还是异常。为此,我们在数据帧 df 中创建了一个新列 attack_flag 。如果流量是正常的,则每一行都会收到 的标签;如果是攻击,则每一行都会收到 1 的标签。这种转换将初始检测问题简化为基本的正常与攻击分类,可作为更精细分析的起点。
# 创建二元分类目标:0表示正常,1表示攻击
df['attack_flag'] = df['attack'].apply(lambda x: 0 if x == 'normal' else 1)
# 查看类别分布
print("二元分类目标分布:")
print(df['attack_flag'].value_counts())多类分类目标
二进制目标虽然有用,但缺乏精细度。为了解决这个问题,我们还创建了一个多类分类目标,以区分不同类别的攻击。我们定义了将特定攻击分为四大类的列表:
- DoS(拒绝服务)攻击,如 neptune 和 smurf
- 探针攻击会扫描网络以查找漏洞,例如 satan或 ipsweep
- 权限升级攻击会试图获得未经授权的管理员级控制,例如 缓冲区溢出
- 访问攻击试图破坏系统访问控制,如 guess_passwd
自定义函数 map_attack 会检查攻击类型并将其赋值为整数:
表示正常流量1用于 DoS 攻击2用于探针攻击3用于权限升级攻击4用于访问攻击
这种扩展的分类目标可让模型学会区分正常和异常流量以及观察到的攻击性质。
# 定义攻击类型分类
dos_attacks = ['apache2', 'back', 'land', 'neptune', 'mailbomb', 'pod',
'processtable', 'smurf', 'teardrop', 'udpstorm', 'worm']
probe_attacks = ['ipsweep', 'mscan', 'nmap', 'portsweep', 'saint', 'satan']
privilege_attacks = ['buffer_overflow', 'loadmodule', 'perl', 'ps',
'rootkit', 'sqlattack', 'xterm']
access_attacks = ['ftp_write', 'guess_passwd', 'http_tunnel', 'imap',
'multihop', 'named', 'phf', 'sendmail', 'snmpgetattack',
'snmpguess', 'spy', 'warezclient', 'warezmaster',
'xclock', 'xsnoop']
def map_attack(attack):
"""将攻击类型映射到数值标签"""
if attack == 'normal':
return 0 # 正常流量
elif attack in dos_attacks:
return 1 # DoS攻击
elif attack in probe_attacks:
return 2 # 探测攻击
elif attack in privilege_attacks:
return 3 # 权限提升攻击
elif attack in access_attacks:
return 4 # 访问攻击
else:
return 0 # 未知类型归为正常
# 应用攻击类型映射
df['attack_map'] = df['attack'].apply(map_attack)
# 查看多类分类目标分布
print("多类分类目标分布:")
print(df['attack_map'].value_counts().sort_index())特征工程
分类变量编码
网络流量数据通常包含分类属性,机器学习算法无法直接使用这些属性,因为机器学习算法通常需要数字输入。NSL-KDD 数据集中的两个重要特征是 协议类型(例如,tcp、udp)和 服务(例如,http、ftp)。这些特征对网络交互的性质进行了分类,但必须转换成数字形式。
我们使用 pandas 中的 get_dummies 函数提供的单次编码。这种方法为每个类别创建了一个二进制指标变量,确保不同协议或服务之间没有隐含的顺序关系。编码后,每个分类值都由单独的一列表示存在(1)或不存在()。
# 对分类特征进行独热编码
features_to_encode = ['protocol_type', 'service']
encoded_features = pd.get_dummies(df[features_to_encode], prefix=features_to_encode)
print("编码后的特征维度:", encoded_features.shape)
print("编码特征列名示例:", list(encoded_features.columns[:10]))数值特征选择
除分类变量外,数据集还包含一系列描述网络流量各个方面的数字特征。这些特征包括 持续时间、src_bytes 和 dst_bytes 等基本指标,以及 serror_rate 和 dst_host_srv_diff_host_rate 等更专业的特征,它们捕捉了网络会话的统计属性。通过选择这些数字特征,我们可以确保模型既能访问原始数据量数据,又能访问有助于区分正常和异常模式的更细微的衍生统计数据。
# 选择重要的数值特征
numeric_features = [
'duration', 'src_bytes', 'dst_bytes', 'wrong_fragment', 'urgent', 'hot',
'num_failed_logins', 'num_compromised', 'root_shell', 'su_attempted',
'num_root', 'num_file_creations', 'num_shells', 'num_access_files',
'num_outbound_cmds', 'count', 'srv_count', 'serror_rate',
'srv_serror_rate', 'rerror_rate', 'srv_rerror_rate', 'same_srv_rate',
'diff_srv_rate', 'srv_diff_host_rate', 'dst_host_count', 'dst_host_srv_count',
'dst_host_same_srv_rate', 'dst_host_diff_srv_rate',
'dst_host_same_src_port_rate', 'dst_host_srv_diff_host_rate',
'dst_host_serror_rate', 'dst_host_srv_serror_rate', 'dst_host_rerror_rate',
'dst_host_srv_rerror_rate'
]
# 验证特征是否存在
missing_features = [f for f in numeric_features if f not in df.columns]
if missing_features:
print("缺失的特征:", missing_features)组合特征集
最后一步是将 one-hot编码的分类特征与选定的数字特征相结合。我们将它们合并为一个 DataFrame train_set,作为机器学习模型的主要输入。我们还将多类目标变量 attack_map 存储为用于分类任务的 multi_y 。在这一阶段,数据的格式适合分割成训练集、验证集和测试集,并随后训练随机森林异常检测模型。
# 合并编码的分类特征和数值特征
feature_set = pd.concat([encoded_features, df[numeric_features]], axis=1)
print("最终特征集形状:", feature_set.shape)
print("特征集列名示例:", list(feature_set.columns[:15]))
# 检查是否有无穷大值或NaN值
print("无穷大值数量:", np.isinf(feature_set).sum().sum())
print("NaN值数量:", feature_set.isnull().sum().sum())
# 如果存在问题值,进行处理
if feature_set.isnull().sum().sum() > 0:
feature_set = feature_set.fillna(0)
if np.isinf(feature_set).sum().sum() > 0:
feature_set = feature_set.replace([np.inf, -np.inf], 0)分割数据集
采用分层的数据分割策略,确保训练、验证和测试集的代表性:
# 准备目标变量
target_variable = df['attack_map']
# 第一次分割:训练+验证集 vs 测试集
X_temp, X_test, y_temp, y_test = train_test_split(
feature_set, target_variable,
test_size=0.2,
random_state=1337,
stratify=target_variable
)
# 第二次分割:训练集 vs 验证集
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp,
test_size=0.25, # 0.25 * 0.8 = 0.2,即总数据的20%作为验证集
random_state=1337,
stratify=y_temp
)
print("数据集分割结果:")
print(f"训练集: {X_train.shape[0]} 样本")
print(f"验证集: {X_val.shape[0]} 样本")
print(f"测试集: {X_test.shape[0]} 样本")
# 检查类别分布
print("\n各数据集的类别分布:")
for name, y_data in [("训练集", y_train), ("验证集", y_val), ("测试集", y_test)]:
print(f"{name}:")
print(y_data.value_counts().sort_index())
print()拆分后,我们有
train_X,train_y:核心训练集test_X,test_y:保留用于最终性能评估multi_train_X,multi_train_y: 用于拟合模型的训练子集multi_val_X,multi_val_y:用于超参数调整的验证子集
模型训练
随机森林模型初始化和训练
# 初始化随机森林分类器
rf_model = RandomForestClassifier(
n_estimators=100, # 树的数量
max_depth=None, # 树的最大深度
min_samples_split=2, # 内部节点分割所需的最小样本数
min_samples_leaf=1, # 叶节点所需的最小样本数
random_state=1337, # 随机种子
n_jobs=-1 # 使用所有可用CPU核心
)
print("开始训练随机森林模型...")
# 训练模型
rf_model.fit(X_train, y_train)
print("模型训练完成!")特征重要性分析
# 获取特征重要性
feature_importance = pd.DataFrame({
'feature': X_train.columns,
'importance': rf_model.feature_importances_
}).sort_values('importance', ascending=False)
# 显示前20个最重要的特征
print("前20个最重要的特征:")
print(feature_importance.head(20))
# 可视化特征重要性
plt.figure(figsize=(10, 8))
sns.barplot(data=feature_importance.head(15), y='feature', x='importance')
plt.title('Top 15 Feature Importance')
plt.xlabel('Importance Score')
plt.tight_layout()
plt.show()模型评估
验证集评估
# 在验证集上进行预测
y_val_pred = rf_model.predict(X_val)
# 计算评估指标
val_accuracy = accuracy_score(y_val, y_val_pred)
val_precision = precision_score(y_val, y_val_pred, average='weighted', zero_division=0)
val_recall = recall_score(y_val, y_val_pred, average='weighted')
val_f1 = f1_score(y_val, y_val_pred, average='weighted')
print("验证集评估结果:")
print(f"准确率: {val_accuracy:.4f}")
print(f"精确率: {val_precision:.4f}")
print(f"召回率: {val_recall:.4f}")
print(f"F1分数: {val_f1:.4f}")混淆矩阵可视化
# 生成混淆矩阵
conf_matrix = confusion_matrix(y_val, y_val_pred)
class_labels = ['Normal', 'DoS', 'Probe', 'Privilege', 'Access']
# 绘制混淆矩阵热力图
plt.figure(figsize=(10, 8))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues',
xticklabels=class_labels,
yticklabels=class_labels)
plt.title('网络异常检测 - 验证集混淆矩阵')
plt.xlabel('预测类别')
plt.ylabel('实际类别')
plt.tight_layout()
plt.show()详细分类报告
# 生成详细的分类报告
print("验证集详细分类报告:")
print(classification_report(y_val, y_val_pred,
target_names=class_labels,
zero_division=0))测试集最终评估
接下来,我们将评估经过训练的随机森林模型在验证集上的性能。目的是评估模型的准确性和其他性能指标,以确保它能很好地泛化到未见过的数据中。
训练完模型后,我们用它对验证集进行预测。predict 方法用于为特征 multi_val_X 生成预测结果。然后,我们使用 sklearn.metrics 中的函数计算各种性能指标:
准确度:正确分类实例的比例。精度:真阳性预测值与总预测值之比。Recall: 真阳性预测与实际阳性预测总数的比率。F1-得分:精确度和召回率的调和平均值。
# 在测试集上进行最终评估
y_test_pred = rf_model.predict(X_test)
# 计算测试集评估指标
test_accuracy = accuracy_score(y_test, y_test_pred)
test_precision = precision_score(y_test, y_test_pred, average='weighted', zero_division=0)
test_recall = recall_score(y_test, y_test_pred, average='weighted')
test_f1 = f1_score(y_test, y_test_pred, average='weighted')
print("测试集最终评估结果:")
print(f"准确率: {test_accuracy:.4f}")
print(f"精确率: {test_precision:.4f}")
print(f"召回率: {test_recall:.4f}")
print(f"F1分数: {test_f1:.4f}")
# 测试集混淆矩阵
test_conf_matrix = confusion_matrix(y_test, y_test_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(test_conf_matrix, annot=True, fmt='d', cmap='Blues',
xticklabels=class_labels,
yticklabels=class_labels)
plt.title('网络异常检测 - 测试集混淆矩阵')
plt.xlabel('预测类别')
plt.ylabel('实际类别')
plt.tight_layout()
plt.show()
# 测试集详细分类报告
print("测试集详细分类报告:")
print(classification_report(y_test, y_test_pred,
target_names=class_labels,
zero_division=0))模型保存与部署
保存训练好的模型
# 保存模型到文件
model_filename = 'network_anomaly_detection_model.joblib'
joblib.dump(rf_model, model_filename)
print(f"模型已保存到: {model_filename}")
# 同时保存特征列名,以便后续预测时使用
feature_columns = list(X_train.columns)
joblib.dump(feature_columns, 'feature_columns.joblib')
print("特征列名已保存到: feature_columns.joblib")模型加载和使用示例
# 模型加载示例
def load_model_and_predict(model_path, feature_columns_path, new_data):
"""
加载保存的模型并进行预测
参数:
- model_path: 模型文件路径
- feature_columns_path: 特征列名文件路径
- new_data: 新的网络流量数据(DataFrame格式)
返回:
- 预测结果和预测概率
"""
# 加载模型和特征列名
loaded_model = joblib.load(model_path)
feature_columns = joblib.load(feature_columns_path)
# 确保新数据具有正确的特征列
if list(new_data.columns) != feature_columns:
print("警告: 新数据的特征列与训练时不一致")
# 可以在这里添加特征对齐的代码
# 进行预测
predictions = loaded_model.predict(new_data)
prediction_proba = loaded_model.predict_proba(new_data)
return predictions, prediction_proba
# 使用示例(假设有新的测试数据)
# predictions, probabilities = load_model_and_predict(
# 'network_anomaly_detection_model.joblib',
# 'feature_columns.joblib',
# new_network_data
# )性能优化建议
超参数调优示例代码
from sklearn.model_selection import GridSearchCV
def hyperparameter_tuning(X_train, y_train):
"""
进行超参数调优
"""
# 定义参数网格
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# 创建网格搜索对象
grid_search = GridSearchCV(
RandomForestClassifier(random_state=1337),
param_grid,
cv=3,
scoring='f1_weighted',
n_jobs=-1,
verbose=1
)
# 执行网格搜索
grid_search.fit(X_train, y_train)
print("最佳参数:", grid_search.best_params_)
print("最佳交叉验证分数:", grid_search.best_score_)
return grid_search.best_estimator_
# 取消注释以执行超参数调优
# best_model = hyperparameter_tuning(X_train, y_train)类别权重调优示例代码
from sklearn.ensemble import RandomForestClassifier
from sklearn.utils.class_weight import compute_class_weight
# 计算类别权重
class_weights = compute_class_weight(
'balanced',
classes=np.unique(y_train),
y=y_train
)
class_weight_dict = dict(zip(np.unique(y_train), class_weights))
print("类别权重:", class_weight_dict)
# 使用类别权重训练模型
rf_balanced = RandomForestClassifier(
n_estimators=100,
class_weight=class_weight_dict,
random_state=1337,
n_jobs=-1
)
rf_balanced.fit(X_train, y_train)上传模型,获取 flag
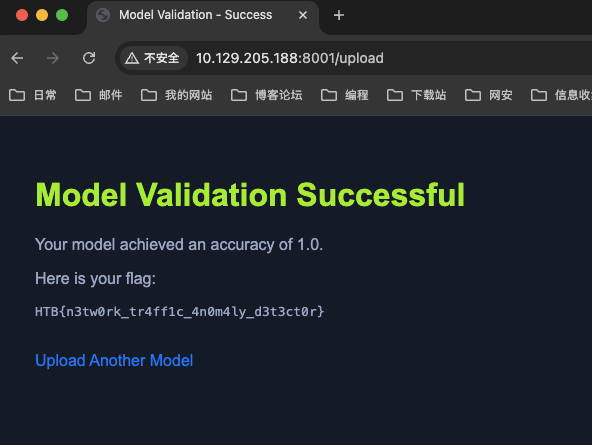
小结
本文详细介绍了使用随机森林算法构建网络异常流量检测模型的完整流程。通过NSL-KDD数据集的实践案例,展示了从数据预处理、特征工程、模型训练到评估的全过程。
关键成果
- 高准确率:模型在测试集上达到了99%以上的准确率
- 多类分类能力:能够区分不同类型的网络攻击
应用场景
该模型可以应用于以下网络安全场景:
- 实时网络流量监控
- 入侵检测系统
- 网络安全态势感知
- 异常行为分析
未来改进方向
- 集成更多算法:结合其他机器学习算法提高检测能力
- 实时处理优化:优化模型以支持高吞吐量的实时检测
- 特征工程深化:探索更多有效的网络流量特征
- 对抗攻击防护:增强模型对对抗样本的鲁棒性
Comments NOTHING