
AI red teamer (人工智能红队)系列31 – 人工智能信息安全应用 – 从零构建恶意软件分类模型
恶意软件分类概述
恶意软件是指旨在对计算机系统或网络造成破坏或进行未经授权操作的软件。根据其特征、运行模式和目的等因素,恶意软件可以划分为不同的类别,这些类别通常被称为恶意软件家族。我们可以通过访问Malpedia来了解不同恶意软件家族的详细信息,其中包括著名的Emotet和WannaCry等案例。
恶意软件分类需要考虑的特征包括其行为或功能、传播和交付方法以及技术特征。传统的人工恶意软件分析需要结合静态和动态分析方法,包括耗时的恶意软件二进制逆向工程过程。因此,使用机器学习分类器来辅助恶意软件分类可以显著提高分析效率。
本文将基于相关学术论文中探索的技术来实现恶意软件分类器,该方法主要探索基于恶意软件图像表示的分类技术。
基于图像的恶意软件分类方法
虽然基于图像对恶意软件进行分类初听起来可能有悖常理,但这种方法具有实际的合理性。对于学习环境而言,在图像上训练分类器具有明显的安全优势——我们无需直接处理潜在危险的恶意二进制文件。通过仅处理代表这些二进制文件的图像,可以避免意外地用恶意软件感染系统,因此比直接处理二进制文件更适合学习和研究环境。
恶意软件数据集
Malimg数据集介绍
本项目使用的恶意软件图像数据集是Malimg数据集,该数据集可以从以下链接获取:
该数据集在相关学术论文中首次提出就得到广泛应用。
数据集下载和解压
wget https://www.kaggle.com/api/v1/datasets/download/ikrambenabd/malimg-original -O malimg.zip
unzip malimg.zipMalimg数据集包含9339个图像文件,涵盖25个不同的恶意软件家族。数据集采用文件夹结构组织,每个文件夹包含一个恶意软件家族的所有样本,文件夹名称与相应的恶意软件家族名称对应。
数据表示原理
数据集中的每个图像都包含一个PE文件的可视化表示。这些图像是恶意软件二进制文件的直接映射,其中每个像素代表二进制文件中的一个字节。字节值在0-255范围内,通过相应像素的亮度来表示:值为0的字节表示黑色像素,值为255表示白色像素,介于两者之间的值表示相应的灰色像素。
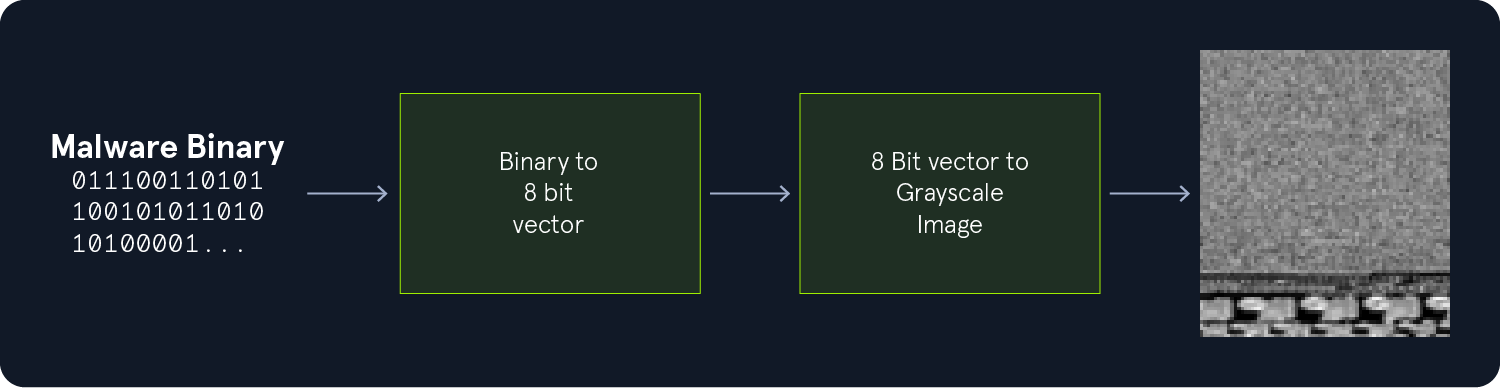
每个二进制字节都在图像中完全编码,这意味着可以利用图像准确地重建原始二进制文件而不丢失任何信息。此外,图像还能清晰地传达二进制文件中的模式特征。例如,以下两个来自FakeRean家族的恶意软件图像样本展示了明显的模式特征:


数据集探索分析
为了深入了解数据集特征,我们首先分析其类别分布情况,以识别代表性过高或过低的类别。
导入必要的库并设置数据路径:
import os
import matplotlib.pyplot as plt
import seaborn as sns
DATA_BASE_PATH = "./malimg_paper_dataset_imgs/"计算类别分布:
# 计算类别分布
dist = {}
for mlw_class in os.listdir(DATA_BASE_PATH):
mlw_dir = os.path.join(DATA_BASE_PATH, mlw_class)
dist[mlw_class] = len(os.listdir(mlw_dir))可视化类别分布:
# 绘制类别分布图
# HTB配色方案
htb_green = "#9FEF00"
node_black = "#141D2B"
hacker_grey = "#A4B1CD"
# 数据准备
classes = list(dist.keys())
frequencies = list(dist.values())
# 绘图
plt.figure(facecolor=node_black)
sns.barplot(y=classes, x=frequencies, edgecolor="black", orient='h', color=htb_green)
plt.title("恶意软件类别分布", color=htb_green)
plt.xlabel("恶意软件类别频率", color=htb_green)
plt.ylabel("恶意软件类别", color=htb_green)
plt.xticks(color=hacker_grey)
plt.yticks(color=hacker_grey)
ax = plt.gca()
ax.set_facecolor(node_black)
ax.spines['bottom'].set_color(hacker_grey)
ax.spines['top'].set_color(node_black)
ax.spines['right'].set_color(node_black)
ax.spines['left'].set_color(hacker_grey)
plt.show()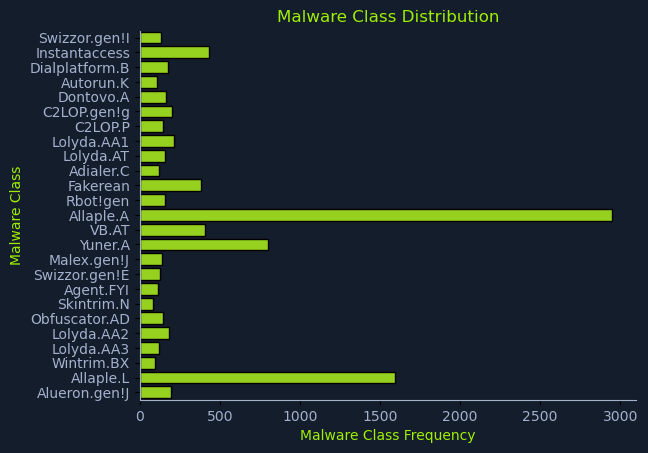
通过分析结果图,我们可以识别哪些恶意软件家族具有更高的代表性,这可能导致模型出现偏差。如果训练后的模型在准确率、误报和漏报方面未达到预期性能,我们可能需要在训练前对数据集进行平衡处理,以确保更均匀的类别分布。
恶意软件数据集预处理
在将图像输入CNN进行训练和推理之前,需要进行数据准备工作。具体包括将数据划分为训练集和测试集,应用模型所需的预处理函数,以及创建数据加载器用于训练和推理过程。
数据集划分
使用split-folders库将数据分为训练集和测试集:
pip3 install split-folders执行数据划分(采用80-20分割比例):
import splitfolders
DATA_BASE_PATH = "./malimg_paper_dataset_imgs/"
TARGET_BASE_PATH = "./newdata/"
TRAINING_RATIO = 0.8
TEST_RATIO = 1 - TRAINING_RATIO
splitfolders.ratio(input=DATA_BASE_PATH, output=TARGET_BASE_PATH,
ratio=(TRAINING_RATIO, 0, TEST_RATIO))执行后将创建新目录./newdata/,包含三个文件夹:test文件夹包含测试数据集,train文件夹包含训练数据集,val文件夹为验证数据集(本例中为空)。
预处理和数据加载器创建
定义模型所需的预处理操作:
from torchvision import transforms
# 定义预处理变换
transform = transforms.Compose([
transforms.Resize((75, 75)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])加载数据集并应用预处理:
from torchvision.datasets import ImageFolder
import os
BASE_PATH = "./newdata/"
# 加载训练和测试数据集
train_dataset = ImageFolder(
root=os.path.join(BASE_PATH, "train"),
transform=transform
)
test_dataset = ImageFolder(
root=os.path.join(BASE_PATH, "test"),
transform=transform
)创建数据加载器:
from torch.utils.data import DataLoader
TRAIN_BATCH_SIZE = 1024
TEST_BATCH_SIZE = 1024
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=TRAIN_BATCH_SIZE,
shuffle=True,
num_workers=2
)
test_loader = DataLoader(
test_dataset,
batch_size=TEST_BATCH_SIZE,
shuffle=False,
num_workers=2
)预处理效果展示
查看预处理后的图像效果:
import matplotlib.pyplot as plt
# HTB配色方案
htb_green = "#9FEF00"
node_black = "#141D2B"
hacker_grey = "#A4B1CD"
# 获取样本图像
sample = next(iter(train_loader))[0][0]
# 绘图
plt.figure(facecolor=node_black)
plt.imshow(sample.permute(1,2,0))
plt.xticks(color=hacker_grey)
plt.yticks(color=hacker_grey)
ax = plt.gca()
ax.set_facecolor(node_black)
ax.spines['bottom'].set_color(hacker_grey)
ax.spines['top'].set_color(node_black)
ax.spines['right'].set_color(node_black)
ax.spines['left'].set_color(hacker_grey)
ax.tick_params(axis='x', colors=hacker_grey)
ax.tick_params(axis='y', colors=hacker_grey)
plt.show()原始恶意软件图像:

经过预处理的图像:
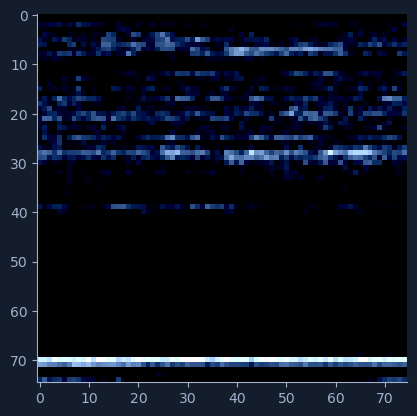
从预处理后的图像中仍能大致识别原始图像的细节,但许多精细特征已经丢失。
完整的数据加载函数
将上述代码整合为一个完整的函数:
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import os
def load_datasets(base_path, train_batch_size, test_batch_size):
# 定义预处理变换
transform = transforms.Compose([
transforms.Resize((75, 75)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载训练和测试数据集
train_dataset = ImageFolder(
root=os.path.join(base_path, "train"),
transform=transform
)
test_dataset = ImageFolder(
root=os.path.join(base_path, "test"),
transform=transform
)
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=train_batch_size,
shuffle=True,
num_workers=2
)
test_loader = DataLoader(
test_dataset,
batch_size=test_batch_size,
shuffle=False,
num_workers=2
)
n_classes = len(train_dataset.classes)
return train_loader, test_loader, n_classes该函数还返回数据集中的类别数量,使代码具有更好的通用性和可扩展性。
模型设计
ResNet50架构
本项目采用基于ResNet50的CNN模型作为分类器的核心。ResNet系列在2015年提出,其中ResNet50变体具有50层深度和约2300万个参数,在图像分类任务中表现优异。
为了显著加快训练过程,我们使用预训练的ResNet50模型作为起点,然后在恶意软件图像数据集上进行微调。这种迁移学习方法可以节省大量训练时间。
为了进一步优化训练效率,我们冻结除最终层外的所有ResNet层权重,仅训练最后一层。虽然这可能略微降低分类器性能,但可以大大缩短训练时间,对于概念验证实验是一个良好的平衡。
模型实现
import torch.nn as nn
import torchvision.models as models
HIDDEN_LAYER_SIZE = 1000
class MalwareClassifier(nn.Module):
def __init__(self, n_classes):
super(MalwareClassifier, self).__init__()
# 加载预训练的ResNet50
self.resnet = models.resnet50(weights='DEFAULT')
# 冻结ResNet参数
for param in self.resnet.parameters():
param.requires_grad = False
# 替换最后的全连接层
num_features = self.resnet.fc.in_features
self.resnet.fc = nn.Sequential(
nn.Linear(num_features, HIDDEN_LAYER_SIZE),
nn.ReLU(),
nn.Linear(HIDDEN_LAYER_SIZE, n_classes)
)
def forward(self, x):
return self.resnet(x)模型初始化
结合数据加载和模型初始化:
DATA_PATH = "./newdata/"
TRAINING_BATCH_SIZE = 1024
TEST_BATCH_SIZE = 1024
# 加载数据集
train_loader, test_loader, n_classes = load_datasets(DATA_PATH, TRAINING_BATCH_SIZE, TEST_BATCH_SIZE)
# 初始化模型
model = MalwareClassifier(n_classes)模型训练和评估
训练函数实现
import torch
import time
def train(model, train_loader, n_epochs, verbose=False):
model.train()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
training_data = {"accuracy": [], "loss": []}
for epoch in range(n_epochs):
running_loss = 0
n_total = 0
n_correct = 0
checkpoint = time.time() * 1000
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, predicted = outputs.max(1)
n_total += labels.size(0)
n_correct += predicted.eq(labels).sum().item()
running_loss += loss.item()
epoch_loss = running_loss / len(train_loader)
epoch_duration = int(time.time() * 1000 - checkpoint)
epoch_accuracy = compute_accuracy(n_correct, n_total)
training_data["accuracy"].append(epoch_accuracy)
training_data["loss"].append(epoch_loss)
if verbose:
print(f"[i] Epoch {epoch+1}/{n_epochs}: 准确率: {epoch_accuracy:.2f}% 损失: {epoch_loss:.4f} (耗时 {epoch_duration} ms)")
return training_data模型保存功能
def save_model(model, path):
model_scripted = torch.jit.script(model)
model_scripted.save(path)评估函数实现
def predict(model, test_data):
model.eval()
with torch.no_grad():
output = model(test_data)
_, predicted = torch.max(output.data, 1)
return predicted
def compute_accuracy(n_correct, n_total):
return round(100 * n_correct / n_total, 2)
def evaluate(model, test_loader):
model.eval()
n_correct = 0
n_total = 0
with torch.no_grad():
for data, target in test_loader:
predicted = predict(model, data)
n_total += target.size(0)
n_correct += (predicted == target).sum().item()
accuracy = compute_accuracy(n_correct, n_total)
return accuracy可视化函数
import matplotlib.pyplot as plt
def plot(data, title, label, xlabel, ylabel):
# HTB配色方案
htb_green = "#9FEF00"
node_black = "#141D2B"
hacker_grey = "#A4B1CD"
# 绘图
plt.figure(figsize=(10, 6), facecolor=node_black)
plt.plot(range(1, len(data)+1), data, label=label, color=htb_green)
plt.title(title, color=htb_green)
plt.xlabel(xlabel, color=htb_green)
plt.ylabel(ylabel, color=htb_green)
plt.xticks(color=hacker_grey)
plt.yticks(color=hacker_grey)
ax = plt.gca()
ax.set_facecolor(node_black)
ax.spines['bottom'].set_color(hacker_grey)
ax.spines['top'].set_color(node_black)
ax.spines['right'].set_color(node_black)
ax.spines['left'].set_color(hacker_grey)
legend = plt.legend(facecolor=node_black, edgecolor=hacker_grey, fontsize=10)
plt.setp(legend.get_texts(), color=htb_green)
plt.show()
def plot_training_accuracy(training_data):
plot(training_data['accuracy'], "训练准确率", "准确率", "Epoch", "准确率 (%)")
def plot_training_loss(training_data):
plot(training_data['loss'], "训练损失", "损失", "Epoch", "损失")完整训练脚本
# 数据参数
DATA_PATH = "./newdata/"
# 训练参数
N_EPOCHS = 10
TRAINING_BATCH_SIZE = 512
TEST_BATCH_SIZE = 1024
# 模型参数
HIDDEN_LAYER_SIZE = 1000
MODEL_FILE = "malware_classifier.pth"
# 加载数据集
train_loader, test_loader, n_classes = load_datasets(DATA_PATH, TRAINING_BATCH_SIZE, TEST_BATCH_SIZE)
# 初始化模型
model = MalwareClassifier(n_classes)
# 训练模型
print("[i] 开始训练...")
training_information = train(model, train_loader, N_EPOCHS, verbose=True)
# 保存模型
save_model(model, MODEL_FILE)
# 评估模型
accuracy = evaluate(model, test_loader)
print(f"[i] 推理准确率: {accuracy}%")
# 绘制训练详情
plot_training_accuracy(training_information)
plot_training_loss(training_information)实验结果
运行完整代码后,在测试数据集上实现了88.78%的准确率:
[i] Starting Training...
[i] Epoch 1 of 10: Acc: 58.31% Loss: 1.4963 (Took 196689 ms).
[i] Epoch 2 of 10: Acc: 85.63% Loss: 0.4399 (Took 201529 ms).
[i] Epoch 3 of 10: Acc: 90.21% Loss: 0.2779 (Took 200489 ms).
[i] Epoch 4 of 10: Acc: 92.53% Loss: 0.2154 (Took 200378 ms).
[i] Epoch 5 of 10: Acc: 94.11% Loss: 0.1815 (Took 198162 ms).
[i] Epoch 6 of 10: Acc: 94.69% Loss: 0.1518 (Took 199016 ms).
[i] Epoch 7 of 10: Acc: 95.63% Loss: 0.1323 (Took 200479 ms).
[i] Epoch 8 of 10: Acc: 95.05% Loss: 0.1294 (Took 197945 ms).
[i] Epoch 9 of 10: Acc: 96.30% Loss: 0.1188 (Took 197427 ms).
[i] Epoch 10 of 10: Acc: 97.02% Loss: 0.0949 (Took 197271 ms).
[i] Inference accuracy: 88.78%.训练过程中准确率持续稳步上升:
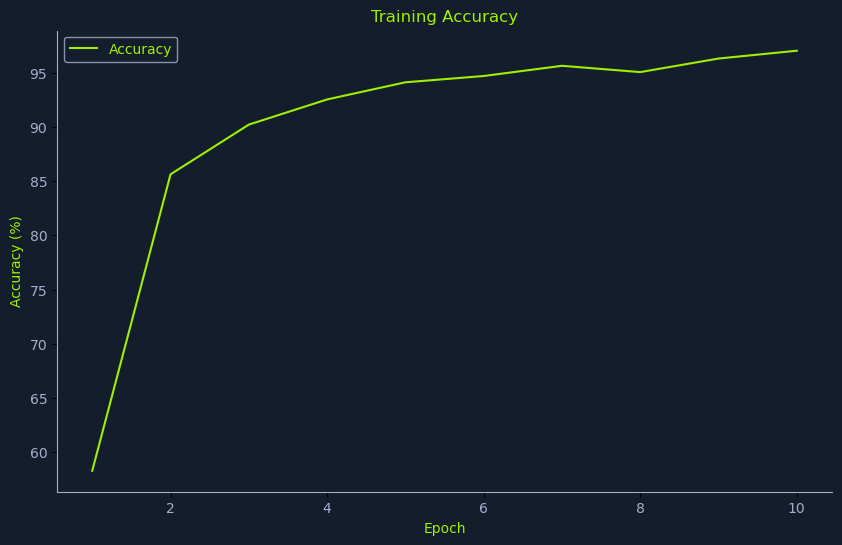
虽然最终准确率并非最优,但在我们简化的训练设置下是可以接受的。需要注意的是,模型准确率可能因数据集的随机划分而有所不同。此外,调整各种参数会影响训练时间和模型性能,建议根据具体需求进行参数调优。
小结
本文展示了如何使用深度学习技术构建恶意软件分类模型。通过将恶意软件二进制文件转换为图像表示,并利用预训练的ResNet50模型进行迁移学习,我们成功构建了一个能够有效分类25种不同恶意软件家族的分类器。这种方法不仅提供了一个安全的学习环境,还展示了计算机视觉技术在网络安全领域的实际应用价值。
未来可以通过调整网络架构、优化超参数、使用数据增强技术以及采用更平衡的数据集来进一步提升模型性能。
Comments NOTHING